收获
通过这题,我应该把 “先排序,再处理”,作为每次解题的常规思路之一。尤其是像字符串,数字的查找这类问题。一组有序元素,会让问题的难度大幅下降。
题目
Write a function to find the longest common prefix string amongst an array of strings.
Ex: For aaabbb and aaaccc, their common prefix is aaa。
暴力遍历 \(O(mn)\)
从头开始遍历,找到反例就返回当前最长共有前缀。一开始就确定最短字符串的长度,减少每次判断的开销。复杂度\(O(mn)\)。m是最短字符串的长度,n是字符串数组的规模。
代码
public class Solution {
public String longestCommonPrefix(String[] strs) {
if (strs.length == 0) { return ""; }
if (strs.length == 1) { return strs[0]; }
int maxLen = Integer.MAX_VALUE;
for (String str : strs) {
maxLen = Math.min(maxLen,str.length());
}
outerFor:
for (int i = 0; i < maxLen; i++) {
char c = strs[0].charAt(i);
for (String str : strs) {
if (str.charAt(i) != c) {
return strs[0].substring(0,i);
}
}
}
return strs[0].substring(0,maxLen);
}
}
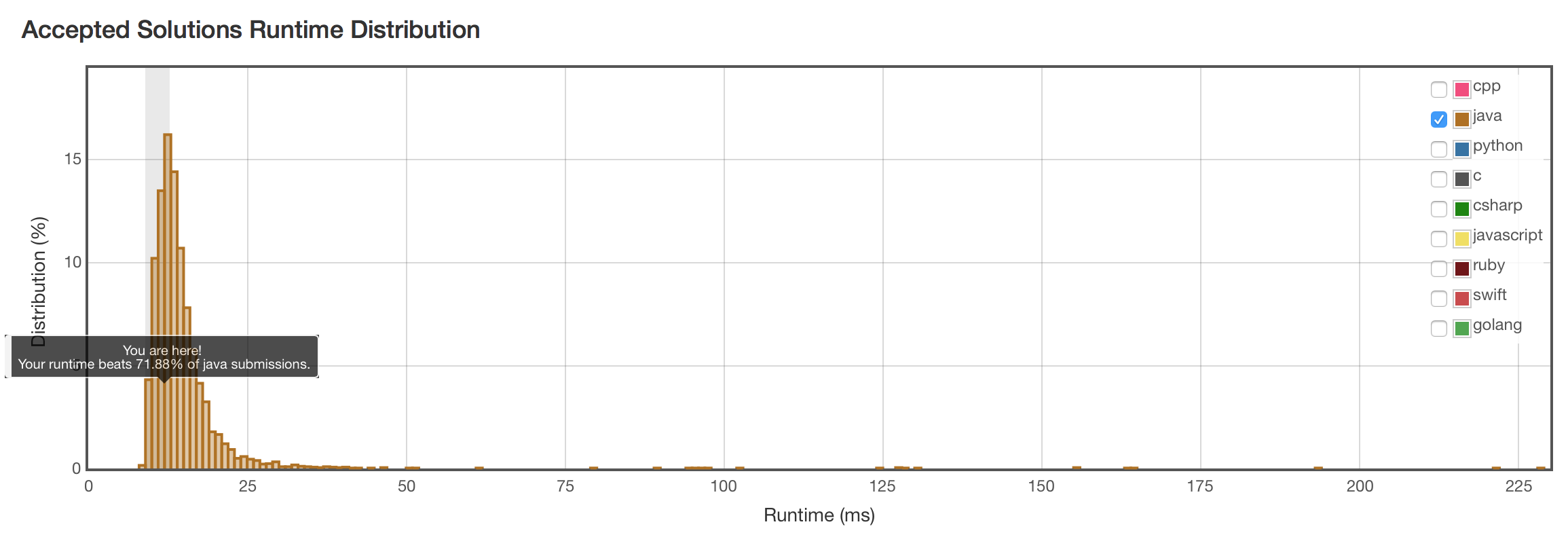
结果
结果已经不错。
递归分治二分查找 \(O(n\log{}{n})\)
这题不适合用分治二分查找。因为前缀相同的条件是每个字符都相同,二分查找如果中位字符相同,不能说明问题,还需要继续进行左递归和右递归。最坏情况是: \(f(m)=2f(m/2)+n\),根据主定理的case 2: 复杂度渐进于\(O(n\log{}{n})\)(假设m和n中,n较大)。
代码
public class Solution {
public String longestCommonPrefix(String[] strs) {
if (strs.length == 0) { return ""; }
if (strs.length == 1) { return strs[0]; }
int maxLen = Integer.MAX_VALUE;
for (String str : strs) { // 每层递归代价: O(n)
maxLen = Math.min(maxLen,str.length());
}
return longestCommonPrefixRecursive(strs,0,maxLen-1);
}
private String longestCommonPrefixRecursive(String[] strs, int low, int high) {
System.out.println("low = " + low + ", high = " + high);
// base case
if (high - low < 0) {
return "";
}
int median = low + ((high-low)/2);
char c = strs[0].charAt(median);
for (String str : strs) {
if (str.charAt(median) != c) {
return longestCommonPrefixRecursive(strs,low,median-1);
}
}
String leftPrefix = longestCommonPrefixRecursive(strs,low,median-1);
if (leftPrefix.length() == (median-low) || (median - low) < 0) {
return leftPrefix + c + longestCommonPrefixRecursive(strs,median+1,high);
} else {
return leftPrefix;
}
}
}
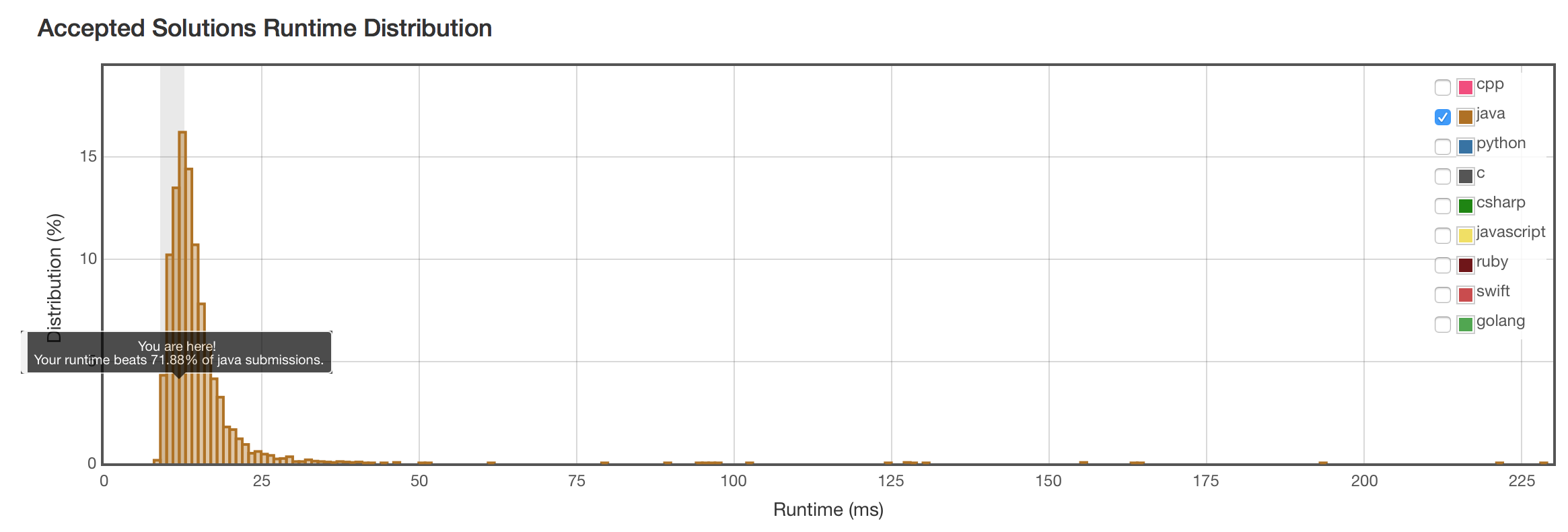
结果
利用库函数indexOf() \(O(m^2n^2)\)
取出数组第一个元素,对其余所有元素遍历做indexOf查询。结果都为0说明是共有前缀。复杂度最坏情况是\(O(m^2n^2)\), m代表首元素的长度,n代表String数组的规模。因为遍历的规模是\(O(mn)\), indexOf()的复杂度是\(O(mn)\)。
代码
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) { return ""; }
if (strs.length == 1) { return strs[0]; }
outerFor:
for (int i = strs[0].length() ; i > 0; i--) {
innerFor:
for (int j = 1; j < strs.length; j++) {
if (strs[j].indexOf(strs[0].substring(0,i)) != 0) { continue outerFor; }
}
return strs[0].substring(0,i);
}
return "";
}
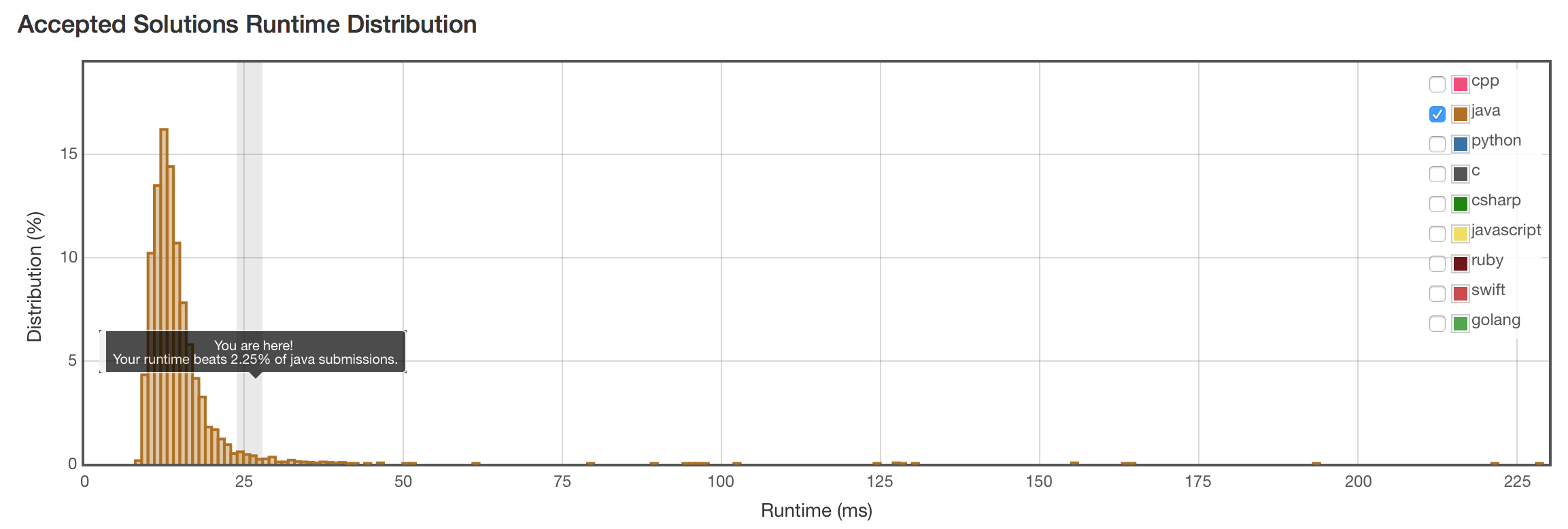
结果
没有比以字符为单位比较更快。也映证了String的indexOf() \(O(mn)\)复杂度的效率确实不高。
排序只比较首尾元素
排序是本题真正的银弹。排序(不能用Stirng.CASE_INSENSITIVE_ORDER)以后,首尾元素是差距最远的两个元素。
aaa
aaabbb
aaabc
aaaccccc
总体复杂度由排序复杂度\(O(n\log_{}{n})\)主导。
代码
public class Solution {
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) { return ""; }
if (strs.length == 1) { return strs[0]; }
Arrays.sort(strs);
char[] first = strs[0].toCharArray();
char[] last = strs[strs.length-1].toCharArray();
int length = Math.min(first.length,last.length);
for (int i = 0; i < length; i++) {
if (first[i] != last[i]) { return new String(Arrays.copyOf(first,i)); }
}
return new String(Arrays.copyOf(first,length));
}
}
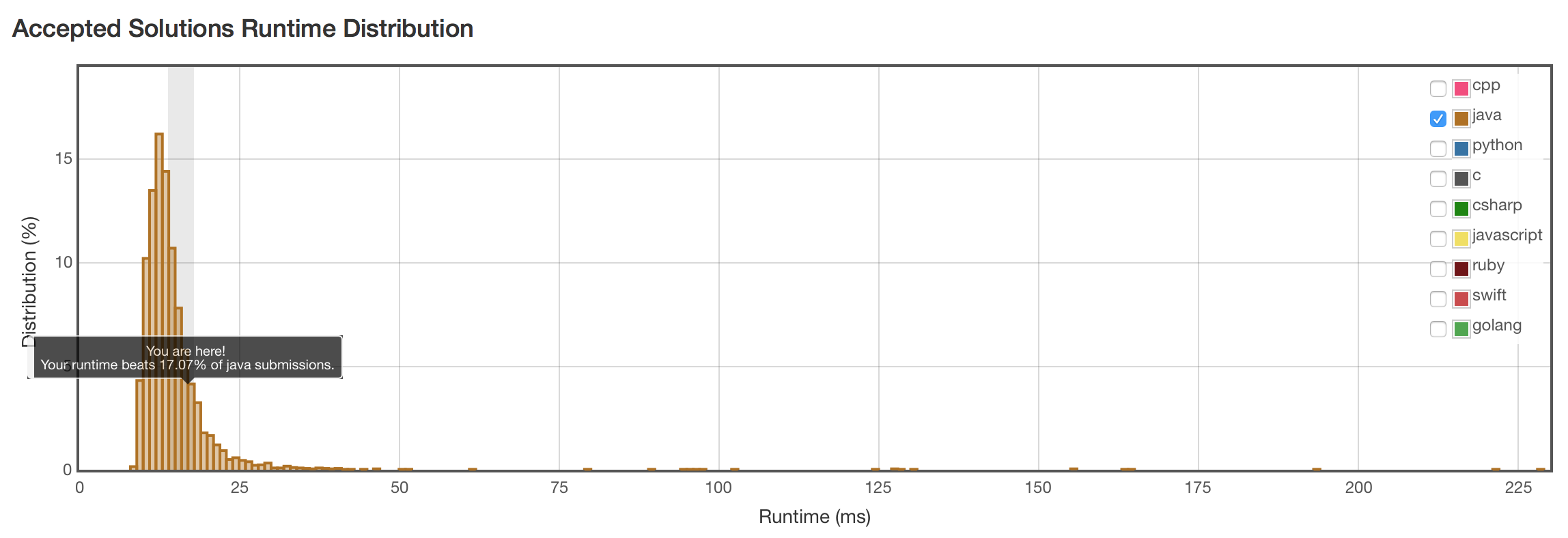
结果
效果好。